Generation of Sentences in Testing/Interactive mode
What will see in this article:- Overview of the Sentence generation using an RNN.
- Various methods used for Searching during the generation E.g. Beamsearch, Sample. TODO: Sample
The surface-realisation from a trained model, is obtained through the sequential process of over-generation and reranking taken from the paper 1. Beam-Search is used first to generate 20 utterances with the beamwidth=10 on decoding criteria of average log-likelihood of the utterance. With the following reranking criteria, top 5 realisations are selected:
where, $\mathcal{L}(\theta)$ denotes cost (loss actually, due to this '$-$' sign is used in the formula) with parameter $\theta$, $\lambda$ is a trade-off constant for penalising ERR (usually kept a high value e.g. 10 or more )and ERR is slot error rate, computed by exact matching of the slot-tokens in the cadidate utterances. $\mathcal{L}(\theta)$ is estimated by the BeamSearch algorithm discussed below.
The generation process starts with the loading of the parameters as list below:
- Wemb_np (Word Embedding Parameters) : (330, 100)
- Wgate_np (Central Gate Parameters) : (200, 300)
- Wrgate_np (Reading Gate Parameters) : (334, 134)
- Wcx_np (Input Gate Parameters) : (200, 100)
- Wfc_np (Forget Gate Parameters) : (149, 100)
- Who_np (Output Gate Parameters) : (100, 330)
Summing up all leads to total 205656 number of parameters. Here, hidden_layer size is set to 100. 330 is the vocab-size. 134 is number of slot-value pairs. Wcxc_np is for overriding, memory cell. Wfc_np is for 1-hot DA-vector. Who_np is used to obtain hidden-to-output_word.
Testing data (file 'test.json') is read by a DataReader.py program which loads entire testing data in the tuples of $[ feat, dact, sent, base ]$ for each testing example. There are 597 testing examples. A testing-example is shown below how it get processed by the 'DataReader.py':
[
"inform(name=काठी एक्सप्रेस;pricerange=महंगा;kidsallowed=yes)",
"काठी एक्सप्रेस एक महंगा रेस्ट्रोरेंट है जहाँ बच्चों का आना मना नहीं है ।",
"काठी एक्सप्रेस एक अच्छी जगह है, जहां बच्चों की अनुमति है और यह महंगा प्राइस में है ."
]
Output:
feat = [('a', u'inform'), (u'name', 'SLOT_NAME'), (u'pricerange', 'SLOT_PRICERANGE'), (u'kidsallowed', u'yes')],
dact = u'inform(name=काठी एक्सप्रेस;pricerange=महंगा;kidsallowed=yes)',
delex_sent = u'SLOT_NAME एक SLOT_PRICERANGE रेस्ट्रोरेंट है जहाँ बच्चों का आना मना नहीं है',
base_sent = u'SLOT_NAME एक अच्छी जगह है, जहां बच्चों की अनुमति है और यह SLOT_PRICERANGE प्राइस में है'
a,sv,s,v,sents,dact,bases,cutoff_b,cutoff_f
a = (array([[7]], dtype=int32),
sv = array([[ 78, 82, 101]], dtype=int32),
s = array([[22, 24, 31]], dtype=int32),
v = array([[7, 1, 1]], dtype=int32),
sents = [[u' काठी एक्सप्रेस एक महंगा रेस्ट्रोरेंट है जहाँ बच्चों का आना मना नहीं है', u' काठी एक्सप्रेस एक महंगा भोजनालय है जहाँ पे आप अपने बच्चों को भी साथ ला सकते हैं।', u' काठी एक्सप्रेस एक महंगा भोजनालय है जहाँ बच्चे भी जा सकते हैं', u' काठी एक्सप्रेस एक महंगा भोजनालय है जहाँ बच्चे भी जा सकते हैं', u' काठी एक्सप्रेस एक महंगा भोजनालय है जहाँ पे आप अपने बच्चों को भी साथ ला सकते हैं।', u' काठी एक्सप्रेस एक महंगा रेस्टोरेंट है जहाँ बच्चे भी जा सकते हैं', u' काठी एक्सप्रेस एक महंगा रेस्ट्रोरेंट है जहाँ बच्चों का आना मना नहीं है', u' काठी एक्सप्रेस महंगा एवं अच्छा भोजनालय जहाँ बच्चों को आने की अनुमति है']],
dact = [u'inform(name=काठी एक्सप्रेस;pricerange=महंगा;kidsallowed=yes)'],
bases = [[u' काठी एक्सप्रेस एक अच्छी जगह है, जहां बच्चों की अनुमति है और यह महंगा प्राइस में है', u' काठी एक्सप्रेस एक अच्छी जगह है, जहां बच्चों की अनुमति है और यह महंगा प्राइस में है', u' काठी एक्सप्रेस एक अच्छी जगह है, यह महंगा प्राइस में है और जहां बच्चों की अनुमति है', u' काठी एक्सप्रेस एक अच्छी जगह है, यह महंगा प्राइस में है और जहां बच्चों की अनुमति है', u' काठी एक्सप्रेस एक अच्छी जगह है, जहां बच्चों की अनुमति है और यह महंगा प्राइस में है', u' काठी एक्सप्रेस एक अच्छी जगह है, जहां बच्चों की अनुमति है और यह महंगा प्राइस में है', u' काठी एक्सप्रेस एक अच्छी जगह है, जहां बच्चों की अनुमति है और यह महंगा प्राइस में है', u' काठी एक्सप्रेस एक अच्छी जगह है, जहां बच्चों की अनुमति है और यह महंगा प्राइस में है']],
cutoff_b = 1,
cutoff_f = array([], shape=(5, 0), dtype=int32))
In one batch of testing, data is received from DataReader.py in the form of \[ a, sv, s, v, sents ,dact ,bases ,cutoff_b, cutoff_f \], where a, sv, s and v are the vector of cardinality, sent and bases are group of utterances belongs to similar dacts in the testing data. cuttoff_b is current batch size, cutoff_f is the size of padding.
After recieving the data from DataReader.py as per the batch-size, a and sv vectors are send to SCLSTM model's beamSearch(a, sv) function to generating the desired utterances.
# hidden_size = Length of Hidden-Vector
beamSearch(a, sv)
{
# Get 1 hot vector
a = 1hot(a)
sv = 1hot(sv)
# Initial Layer
h0, c0 = zeros(hidden_size), zeros(hidden_size)
# starting node
node = BeamSearchNode(h0,c0,None,eval_score)
node.sv = sv
node.a = a
# Priority Queue for beam search
nodes = PriorityQueue()
nodes.put(node.eval(),node)
qsize = 1
# To store all the generated sentences
endnodes = []
# Start beam-search
while True
{
# Give up when decoding takes too long
if qsize > 10000
break
# Get the best node
score, n = nodes.get()
# if end of sentence achieved
if n.wordid==1 and n.prevNode!=None
{
score = n.eval
endnodes.append((score, n))
# if maximum number of sentences generated
if len(endnodes)>=overgen:
break
else
continue
}
# decode one step of 10(beamwidth) on the current node(n.wordid)
words, probs, sv, c, h = _gen(n) # _gen() implements the decoder and return required variabes\
for w in words:
{
node = BeamSearchNode(h,c,n,eval_score)
node.sv = sv
node.a = a
nodes.put(node.eval(),node)
}
qsize += len(words) - 1
}
# choose nbest paths, back trace them
utts = []
for score,n in sorted(endnodes):
utt = [n.wordid]
while n.prevNode!=None:
# back trace
n = n.prevNode
utt.append(n.wordid)
utt = utt[::-1]
utts.append((score,utt))
return utts
}
Source: SC-LSTM model
The above pseudo-code of beamsearch, uses a python class named BeamSearchNode() to maintain a beam-search tree (an example is shown in fig below). ProrityQueue data-structure has been used store the words sequence obtain from each step by the decoder. Decoder takes a word and generates a sequence of best next words after it, equal to the number of beamwidth which is set 10 in the example. Thus a path is followed step-by-step untill decoder send the end-of-sentence (eos) flag saying that a valid path of words is found as first sentence. After, first choice made, through back-track next best node is selected from the rest in PriorityQueue which generate the next output sentence. In this way multiple output senteces will be generated untill overgen limit reached. Based on all the endnode (Total=20) achieved, 20 output sentences (sequence of words) are collected and send to lexicalisation to convert words from their cadinality(word_id) to its vocab surface-form.
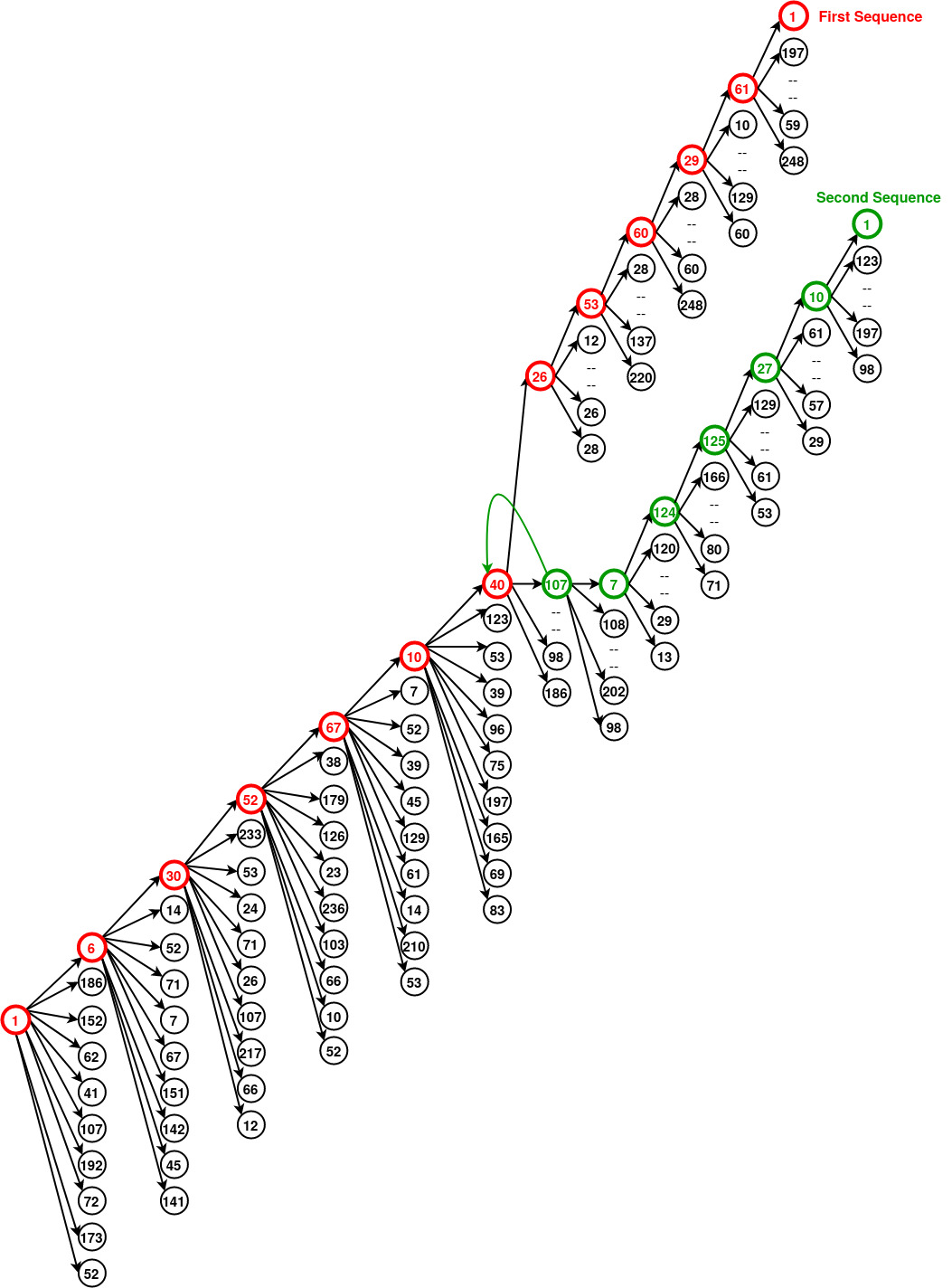
The above figure show the generation of two sequences on input dact 'inform(name=काठी एक्सप्रेस;pricerange=महंगा;kidsallowed=yes)'. First sequence, shown with red color, is \[1, 6, 30, 52, 67, 10, 40, 26, 53, 60, 29, 61, 1\]. After getting the first sequence, next node extraced from PriorityQueue is '107' from which onwards a sequence \[7, 124, 125, 27, 10, 1\] is obtained. Adding the previous sequence to BeamSearchNodes previous to 107 (\[1, 6, 30, 52, 67, 10, 40\]), complete list would be \[1, 6, 30, 52, 67, 10, 40, 107, 7, 124, 125, 27, 10, 1\].
Each Beam node, which consists of network parameters {c,h}, word_id, score, leng (generated length), calculates its eval_score as below, based on which it is going to be extracted when node.get() is called. It is a length-normalized logp score which helps in getting much better results.
Where, eps=$10^{-7}$ to avoice divide-by-zero situation. A Node's logp value which represents its importance in the sequence being considered. logp value of first node is initialised with 0.
Reaching at each endnode (eos), an integral score is estimated for the entire sequence of the words (a sentence) by the last Node.eval_score:
Thus, you can see that BeamSearch job is score all possible eligible sequences by maximizing probability of the sequence.
We take the log here so that log of product becomes sum of a log for doing maths efficiently.
This is the score which help is identifying the topk, utterances from the generated candidates.