Gated RNN based Architectures: Language Generation Become Easier
What will see in this article:- Intro to RNN.
- RNN limitation.
- LSTM discovery.
Subsequently, people have proposed several configurations in the the architecture and its functionality as per the need. RNN now to come every now and then with new design and flavor to attract and astonish the customers (oops programmers actually). For example, RNN was not seems to performing well for language modelling/generation due to its single layer(hidden as usual) architecture (no flavor added). It was acutally suffering from a great disease of vanishing gradient and limiting its power to capture long distant relations. Doctors(researcers actually) having years of experience proposed a cure to it by helping it with three more pills (hidden layer actually) added to the architecture. Thus RNN with this newly added flavor now became LSTM, a great Sequence Modeller with added hidden layers to forget, keep and output the latent parameters in the architectures.
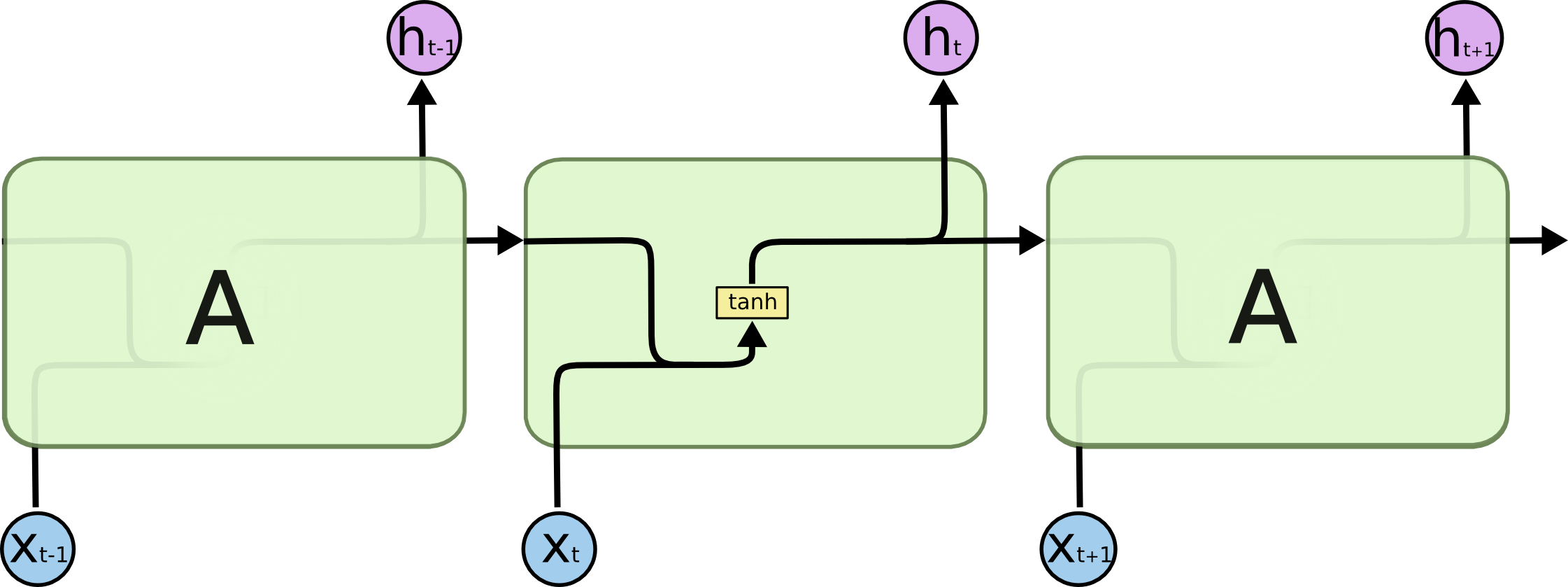
Source: Understanding LSTM Networks
Let's look at the problem (diseass) of vanishing gradient a bit closer. It requires real mathematical understanding of sigmoid function (a perfect activation function), derivation (calculus not biology), gradient and its back-propogation. Look at following examples:
- We, travelling to India, ........... have seen many historical places.
- He, travelling to India, ........... has seen many historical places.
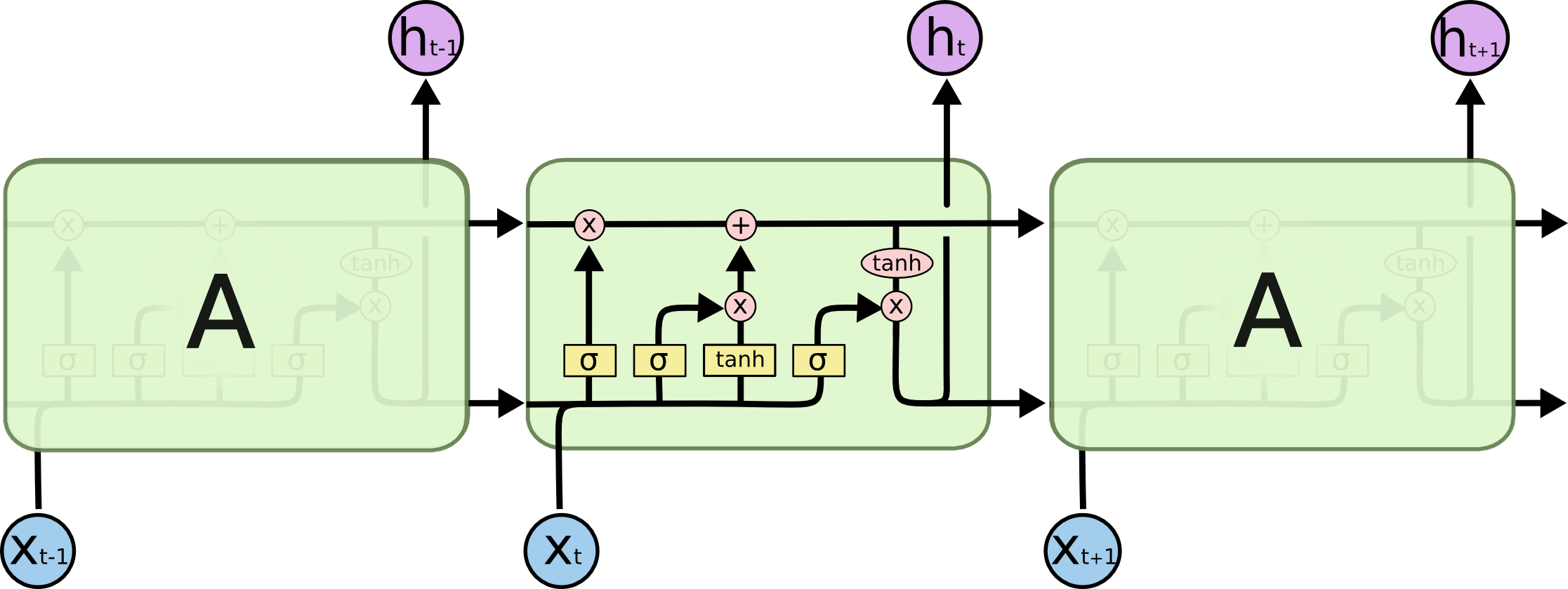
Source: Understanding LSTM Networks
How the LSTM has sort the problem of vanishign gradient? It is answered by a series of illustrative steps. In simple word, a distant relation in a sequence, no matter how distant it is, has to be learned, relearned in order to model the context in more accurately. Clueless? Look at this example:
- Soni went to her room and slept. But, Rahul kept writing ..his...
Try to observe a case of gender depencies. her is dependent on Soni. But in next statement, subject got changed to Rahul now, so the gender detection tool of the LSTM should also be updated. Before updating the, detector property, parameter vector has to be refreshed (forget) in condition with the given input. This entire process was lacking in simple RNN to limit its capablity to effectively establish the relation in a sequence. LSTM is made to own this behaviour naturally .
References
- A deep dive into the world of gated Recurrent Neural Networks: LSTM and GRU blog
- Understanding LSTM Networks blog
- Understanding Gated Recurrent Neural Networks blog
- The Vanishing Gradient Problem blog
- Vanishing Gradients in Recurrent Neural Networks blog
- How to Develop a Word-Level Neural Language Model and Use it to Generate Text blog
- What is the role of “forget gates” in Long Term Short Memory (LSTM)? quora
- Recurrent neural network based language model intspeech10
- Efficient Estimation of Word Representations inVector Space arxiv